 - SF-23 - Gp Singapore 2023")
La strategia di gara in F1 può decidere l’esito di una corsa nel momento in cui la propria vettura è sufficientemente competitiva. Se ne parla da quando è nata la massima categoria del motorsport e progressivamente, nell’arco del tempo, i team hanno sempre più ingrandito i reparti che si occupano della gestione. Nell’oramai lontano 2009, ad esempio, Red Bull effettuò un vero e proprio “restyling” di questo reparto, mettendo a capo del personale persone con molta esperienza nella “teoria del gioco”.
Questo perchè alla fine, semplificando al massimo, il concetto è molto simile. Si è quindi cominciato a utilizzare le così dette “Simulazioni Monte Carlo“. Si tratta di metodo probabilistico che simula giro per giro molte gare una dopo l’altra, differenziando lo scenario di volta in volta. In altre parole, per ogni tornata vengono analizzate diversi scenari percorribili a seconda di vari fattori, come una Safety Car, una Virtual o una bandiera gialla. In questo modo si cerca di prevedere ciò che potrebbe accadere.
Queste simulazioni sono tutt’ora utilizzate e in genere vengono combinate con altri tipi di previsioni. Campi ipotetici che spesso vengono addirittura avviati in corso d’opera durante la gara, inserendo nei calcolatori diversi input sulla base di quello che sta succedendo in pista. In questa maniera, con un accuratezza ridotta, si può cercare di prevedere quello che potrebbe succedere al proprio pilota nei giri successivi.
Dalla stagione 2017 le squadre di F1 hanno preso in considerazione l’utilizzo dell’intelligenza artificiale, scienza che permette di analizzare e trovare dei pattern attraverso la gestione di una grande mole di dati. Il software che si occupa di simulare tramite il “machine learning” le varie situazioni della gara prende il nome di “Race Planner”. Attualmente si è fatto uno step successivo dove viene utilizzato il “Reinforcement learning”, ovvero un metodo in cui non serve etichettare ogni dato e definire quale sia “giusto” o “sbagliato”.

Parliamo di tecnica molto avanzata che adotta un metodo alquanto differente “nell’allenare il modello”. Il grande vantaggio di questa pratica riguarda la capacità di auto apprendimento, utile per imparare comportamenti molto complessi e poter consigliare decisioni sia nel breve che sul lungo termine. In altre parole possiamo dire che il Reinforcement Learning è una tecnica attraverso la quale un computer (agente) impara a svolgere un’attività o un compito tramite ripetute interazioni di tipo “trial-and-error”, ovvero eseguite per tentativi ed errori.
Questo tipo di approccio permette all’agente di prendere decisioni che possano massimizzare la posizione in pista senza l’intervento dell’uomo. Per esempio l’agente può scegliere una strada a breve termine durante la gara che implichi la perdita di alcune posizioni al fine però di riguadagnarle alla fine della corsa. Inoltre, come detto, imparando tramite tentativi ed errori, non serve alcun inserimento di informazioni che etichettino i dati, perchè tutto questo avverrà automaticamente.
F1/Ferrari vs Red Bull, strategie di gara: reinforcement learning
Proseguiamo introducendo il concetto di “controllo”. Tramite il Reinforcement Learning possiamo portare a termine due compiti in base alla “policy” che applichiamo. Con questo termine intendiamo una funzione ed un insieme di regole che specificano quale azione dovrebbe intraprendere l’agente in una data situazione, al fine di massimizzare un certo obiettivo prestabilito definito “reward”. In altre parole, si tratta di una strategia decisionale che l’agente segue per selezionare le azioni.
La prima viene nominata “prediction” e in questo caso la policy è definita e fissata, mirando a predire la bontà di una certa strategia. Si tratta di fatto è il vecchio approccio che la F1 aveva in passato. Sino al 2015, infatti, le squadre selezionavano alcune strategie cercando di capire quel fosse la più rapida o, in generale, la migliore. Si andava pertanto a misurare la mera adattazione di una data policy per ottimizzare la ricompensa (reward) fornita dalla sequenza di azioni intraprese.
Tutto diventa più complesso e interessante nel momento in cui andiamo ad applicare il concetto di “Control” (controllo). In questo caso l’obiettivo dell’agente è quello di trovare l’ottimo, ovvero la auto definizione di una policy che permetta, considerando una qualsiasi situazione in pista, il raggiungimento dello scenario più azzeccato possibile.
Applicando questo concetto alla F1, il controllo analizza e trovare diversi pattern complicati tramite la raccolta dati, adattandosi in tempo reale a ciò che accade. Facciamo un esempio e supponiamo di trovarci nel seguente stato di gara (ciò che viene definito ‘state’). Per farlo utilizzeremo un’immagine, la seguente, per cercare di capire il funzionamento di questi provvedimenti.
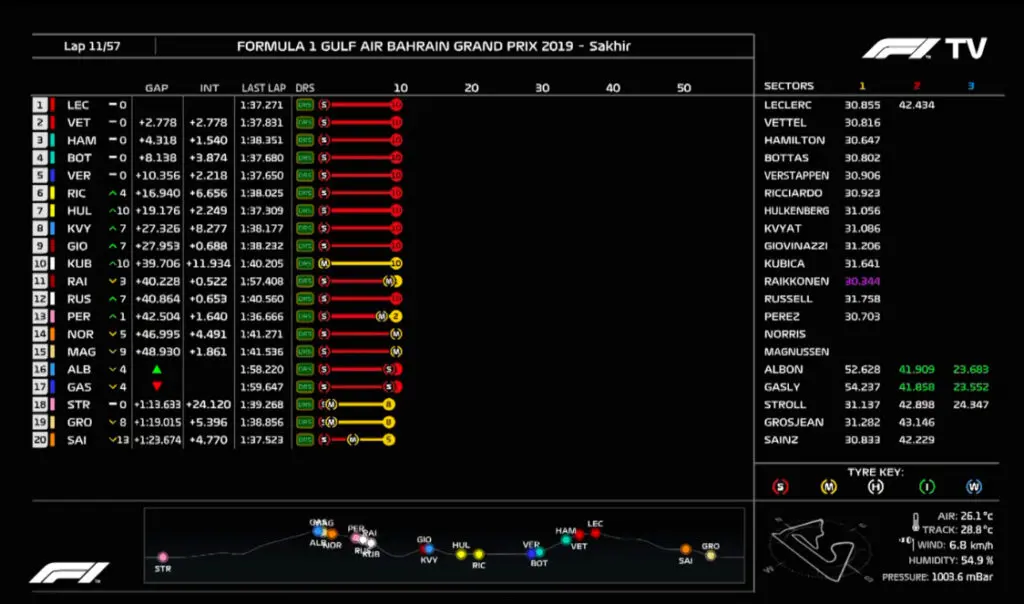
Uno “state” è definito da alcuni parametri come il numero del giro corrente, la classifica istantanea, i distacchi tra i piloti e le gomme che ognuno sta utilizzando con relativo numero di giri di ogni treno di pneumatici. A questo punto una gara può essere formulata attraverso il processo di decisione di Markov (MDP), in cui la probabilità di passare da uno stato ad un altro si basa solamente sull’ultimo stato osservato.
Nel nostro esempio raffigurato dallo scatto precedente, quindi, parliamo dello stato del giro 11. Le tornate dall’1 al 10 hanno pertanto un peso minore su ciò che accadrà allo stato successivo dal passaggio numero 12. Ovviamente per quanto il modello possa essere molto accurato, non definirà mai con certezza cosa accadrà allo stato successivo, anche perchè molti degli eventi in pista sono “stocastici”.
Nel simulare lo stato successivo bisogna prima di tutto stimare il ritmo potenziale di ogni pilota. Questo può essere fatto tramite una funzione che prende in considerazione il compound della gomma, il comportamento che avrà lo pneumatico, il tyre model e la massa di carburante che si abbassa con il passare delle tornate. Ogni giro effettuato introduce un aggiornamento alle variabili osservabili, quali il passo effettivo della vettura, l’età della gomma, l’intervallo tra i piloti e tutto il resto.
Nel prevedere il passaggio successivo l’agente deve prendere in considerazione anche “l’overtake model”, ovvero un modello che tenga conto della probabilità che ha ogni pilota di essere sorpassato o di sorpassare. Il modello basilare prende in input diversi dati per ogni pilota, quali il distacco da chi precede e chi segue, il passo potenziale degli altri competitor e un coefficiente di facilità del sopravanzare un avversario. Inoltre va altresì valutato il “pit lane time”, ovvero il lasso di tempo che si impiega per percorrere tutta la linea dei box effettuando un pit stop.
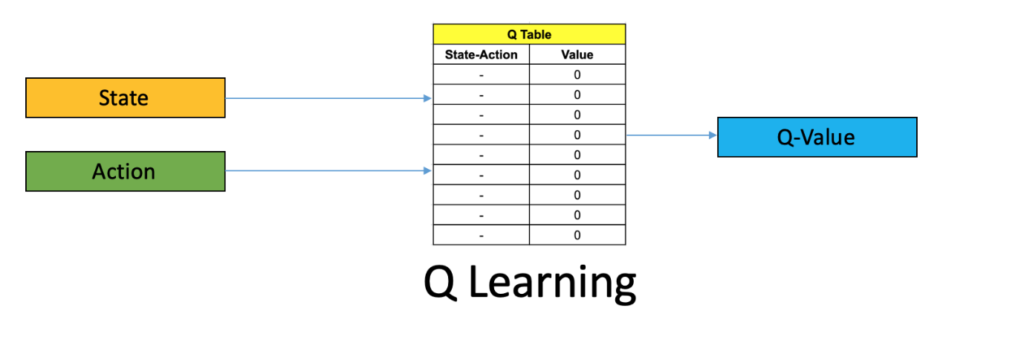
Supponiamo ora che l’agente stia analizzando lo stato corrente della corsa, cercando di predire lo stato “giro successivo” scegliendo la policy più efficace da utilizzare. Ricordiamo che stiamo prendendo in considerazione il compito di Controllo e non di Predizione. Il Q-Learning è una tecnica usata nel RL per scegliere la policy da seguire.
Per ogni stato è possibile valutare l’impatto che avrebbe una certa azione determinata da una specifica policy. Ad ogni associazione stato-azione possiamo abbinare un certo “Q-Value“. In questo modo l’agente potrà decidere quale policy utilizzare in quanto sceglierà l’associazione stato-azione con il maggior Q-Value.
F1, strategie di gara: Red Bull vs Ferrari
La forza dell’RL è proprio questa, ovvero non basarsi solamente sui dati storici, ma interagire con l’ambiente di lavoro. Il linea generale non è sempre possibile farlo ma in F1 diventa possibile. Attualmente Red Bull possiede un certo vantaggio in questo campo, anche se il resto dei team implementano “prediction” tramite l’utilizzo di queste tecniche. La prima partnership con la Oracle, specializzata appunto nell’analisi dati tramite intelligenza artificiale risale al 2021. Ma è dall’anno successivo che l’impresa statunitense diventa il main sponsor della squadra di Milton Keynes.
Parliamo di un lavoro a stretto contatto di gomito che ha permesso di migliorare sempre più la manipolazione e l’utilizzo di questi dati, portando la scuderia austriaca avere un buon vantaggio sui propri competitor. Essenzialmente, durante la gara, Red Bull è in grado di prevedere ciò che accadrà nei 2-3 giri successivi con un’alta accuratezza, il che ovviamente è molto difficile da ottenere.
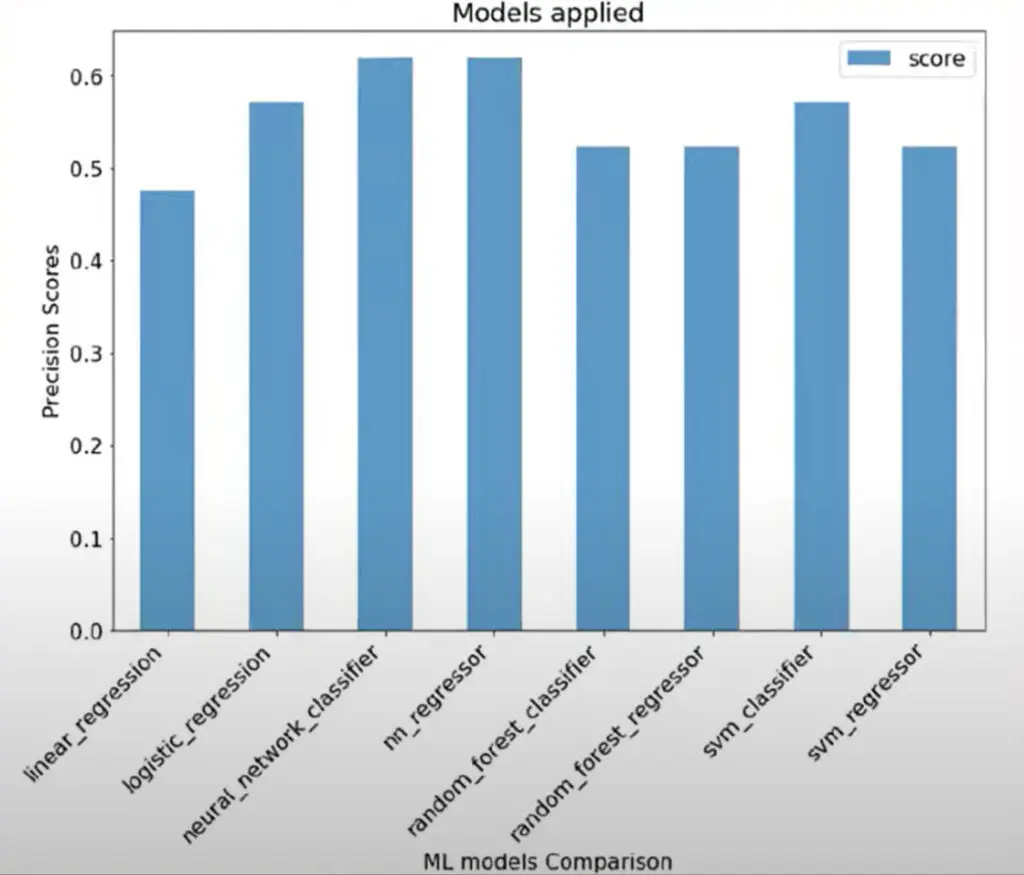
Inoltre a Milton Keynes stanno già utilizzando le reti neurali. Queste sono un sottoinsieme del machine learning e rappresentano l’elemento centrale degli algoritmi del deep learning. Il loro nome e struttura sono ispirati al cervello umano, imitando il modo in cui i neuroni biologici inviano segnali. Analizzando il grafico precedente, preso direttamente dalla banca dati della ditta americana Oracle che mostra i risultati di una loro indagine su diversi tipi di approcci.
Ad ognuna di queste casistiche è stato chiesto di determinare il vincitore di più gare e il punteggio più alto è stato ottenuto proprio dalla rete neurale, che quindi sembra esser la più precisa al momento. Per esser chiari, gli altri team non sono stati certo a guardare. Già nel 2020 James Vowles, al tempo direttore delle strategie Mercedes, affermò che ormai la squadra tedesca utilizzava da tempo l’intelligenza artificiale per la maggior parte degli aspetti che riguardano la strategia di gara.
Infatti, già nel 2018, nell’era di dominio della Stella a tre punte, il team di Brackley aveva cominciato ad approcciarsi ai “Big Data”. Mentre solo nel 2022 la squadra capiì l’importanza di avere un partner strategico mettendo in piedi una partnership con G42, azienda appunto specializzata nell’intelligenza artificiale. E in tutto questo la Ferrari? Beh anche il Cavallino Rampante ha partecipato a questo ‘trend’ e nel 2021 ha siglato l’accordo con AWS, branchia del colosso Amazon dedicata al Machine Learning.
Di fatto però, il team di Maranello ha annunciato AWS come “cloud Partner”. La squadra modenese pertanto, attualmente utilizza Amazon Simple Storage Service (Amazon S3) e AWS Lake Formation per raccogliere, catalogare e pulire in modo rapido e sicuro centinaia di petabyte di dati.

Ai tempi Mattia Binotto sostenne che tale collaborazione avrebbe dato vita a un’organizzazione “data-driven”, quando altre squadre già la possedevano da anni. Tuttavia i vari modelli di AWS dovrebbero servire non solo per analizzare e prendere decisioni relative alla strategia di gara, ma anche per comprendere meglio i dati stessi proveniente dalla pista, quali temperatura, tempi sul giro e livelli di grip. Ovviamente la differenza sta nell’accuratezza della manipolazione e, a quanto pare considerando le strategie della rossa spesso fallimentari, non sembrano esserci modelli capaci di prevedere l’esito dei giri successivi durante la gara.
Autori: Alessandro Arcari – @berrageiz – Niccoló Arnerich – @niccoloarnerich
Immagini: Scuderia Ferrari – Oracle